I apologize in advance - this will have no interest for many & it's a very lengthy post, but maybe someone can help - I have great confidence in the diversity of knowledge on this forum & that there is some expertise who can help.
I am generally pleased with the speed of my Comcast connection here in East Bay Area CA. I measure the advertised 4096 kbps - pretty good (& consistent)
But I have problems however receiving adequate bandwidth from a specific site in the UK from which I receive streaming soccer video through a subscription service. (No ...it's not porn!)
Here's the dilemma - I can use the exact same hardware configuration (i.e. my laptop) and go 1/4 mile down the street to the nearest Starbucks & get a perfect transmission received at full speed (~500K)with no stalling or buffering. Therefor there is no problem with the source having inadequate output. (I've repeated this test several times & get consistent results)
i.e. Same hardware & local settings -> Same target (but reached through different ISP);
One works flawlessly, the other doesn't (has ~50% loss of bandwidth from source media)
Therefor problem must between source & target, right?
But .... If I do a ping & trace route from each location I actually get WORSE latency results from the one that gives me flawless bandwidth transmission (i.e. The Starbucks T mobile connection has worse pings but no bandwidth issue) - I'll post the results below.
When I try to explain the situation to Comcast, it's most frustrating - they either say there's nothing wrong with my ping (which is reasonable) or that there is a problem at step "x" and that is off their network therefor not their problem. When I try to reply there is a response from a different "tech support" agent each time & they never read all the previous details that show it clearly isn't a source or a local equipment/hardware issue. They appear to be answering from pre-scripted "idiot guides" rather than seriously analyzing the issue.
But clearly I have the problem with my Comcast connection, yet not with an alternative (I also get similar good results from my work connection); on my home Comcast connection, it makes no difference whether I use my laptop or home pc; whether connected through the router, or directly to the cable modem, it is unchanged.
How can I diagnose the source of the problem, where it is choking bandwidth, yet the pings appear to be adequate???
Any assistance/suggestions will be most appreciated.
The Starbucks/T-Mobile route - delivers perfect bandwidth at required speed:
Now the Comcast connection suffers quite a loss in bandwidth ~ 1/2 of the required 500kbps
edit: removed the pings & tracert's as found the target media was hosted off the primary site. The problem statement is still accurate & the tracert to actual target is in subsequenst posts below
So maybe I'm getting some packet loss in the TCP handshake?
I downloaded Ethereal so maybe a guru intimate with that can analyze below for me? (I can also forward the entire capture by e-mail if that is helpful?) I've extracted some areas that look like problems ....
(click-able link to full-size picture)

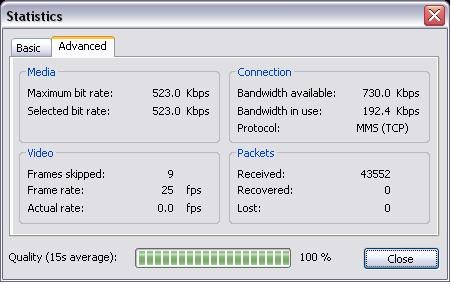
Here is an image of the windows media statistics -
.
I am generally pleased with the speed of my Comcast connection here in East Bay Area CA. I measure the advertised 4096 kbps - pretty good (& consistent)
But I have problems however receiving adequate bandwidth from a specific site in the UK from which I receive streaming soccer video through a subscription service. (No ...it's not porn!)
Here's the dilemma - I can use the exact same hardware configuration (i.e. my laptop) and go 1/4 mile down the street to the nearest Starbucks & get a perfect transmission received at full speed (~500K)with no stalling or buffering. Therefor there is no problem with the source having inadequate output. (I've repeated this test several times & get consistent results)
i.e. Same hardware & local settings -> Same target (but reached through different ISP);
One works flawlessly, the other doesn't (has ~50% loss of bandwidth from source media)
Therefor problem must between source & target, right?
But .... If I do a ping & trace route from each location I actually get WORSE latency results from the one that gives me flawless bandwidth transmission (i.e. The Starbucks T mobile connection has worse pings but no bandwidth issue) - I'll post the results below.
When I try to explain the situation to Comcast, it's most frustrating - they either say there's nothing wrong with my ping (which is reasonable) or that there is a problem at step "x" and that is off their network therefor not their problem. When I try to reply there is a response from a different "tech support" agent each time & they never read all the previous details that show it clearly isn't a source or a local equipment/hardware issue. They appear to be answering from pre-scripted "idiot guides" rather than seriously analyzing the issue.
But clearly I have the problem with my Comcast connection, yet not with an alternative (I also get similar good results from my work connection); on my home Comcast connection, it makes no difference whether I use my laptop or home pc; whether connected through the router, or directly to the cable modem, it is unchanged.
How can I diagnose the source of the problem, where it is choking bandwidth, yet the pings appear to be adequate???
Any assistance/suggestions will be most appreciated.
The Starbucks/T-Mobile route - delivers perfect bandwidth at required speed:
Now the Comcast connection suffers quite a loss in bandwidth ~ 1/2 of the required 500kbps
edit: removed the pings & tracert's as found the target media was hosted off the primary site. The problem statement is still accurate & the tracert to actual target is in subsequenst posts below
So maybe I'm getting some packet loss in the TCP handshake?
I downloaded Ethereal so maybe a guru intimate with that can analyze below for me? (I can also forward the entire capture by e-mail if that is helpful?) I've extracted some areas that look like problems ....
(click-able link to full-size picture)

Here is an image of the windows media statistics -
.
Attachments
Last edited:





 :redface:
:redface: